Plan for Unsuccessful Changes; A Use Case of the AWS Health API

Boardgame
Radlands is a fast-paced card game where you lead a tribe of survivors in a harsh post-apocalyptic world. Your tribe has settled near a rare water source and uses strange old technology from abandoned military experiments to stay alive. Other tribes want your water and are preparing to attack. To win, you’ll need to use your cards wisely, protect your three camps, and perform regular healthchecks to ensure their survival. If all your camps are destroyed, you lose. Radlands is all about strategy, survival, and fierce battles. For more information, visit: boardgamegeek
Resiliency: A Shared Responsibility in the Cloud
This blog post is inspired by the Chalk Talk session titled ARC317 - Operational Excellence: Best Practices for Resilient Systems from AWS re:Invent 2024. You can explore the presentation deck on the AWS events content.
According to the AWS Well-Architected Framework, resiliency is defined as the ability of a system to recover from failures caused by load, attacks, or internal faults. These failures can stem from various sources, such as hardware malfunctions, software bugs, operational errors, or environmental disruptions.
In the cloud era, ensuring resiliency is not solely the responsibility of cloud consumers. Instead, it operates on a shared responsibility model, where both cloud providers and customers play critical roles.
-
AWS's Responsibility: Resiliency of the Cloud
AWS is accountable for the resiliency of the infrastructure that powers its cloud services. This includes managing the hardware, software, networking, and facilities supporting the AWS Cloud. AWS strives to ensure high availability and service reliability, meeting or exceeding its Service Level Agreements (SLAs) through robust infrastructure management. -
Customer's Responsibility: Resiliency in the Cloud
Customers are responsible for configuring and managing the resiliency of their workloads running in the AWS Cloud. The scope of this responsibility depends on the AWS services they choose. For example, a fully managed service like Amazon S3 shifts much of the resiliency burden to AWS, while a self-managed virtual machine in Amazon EC2 requires the customer to implement failover strategies, backups, and other resiliency measures.
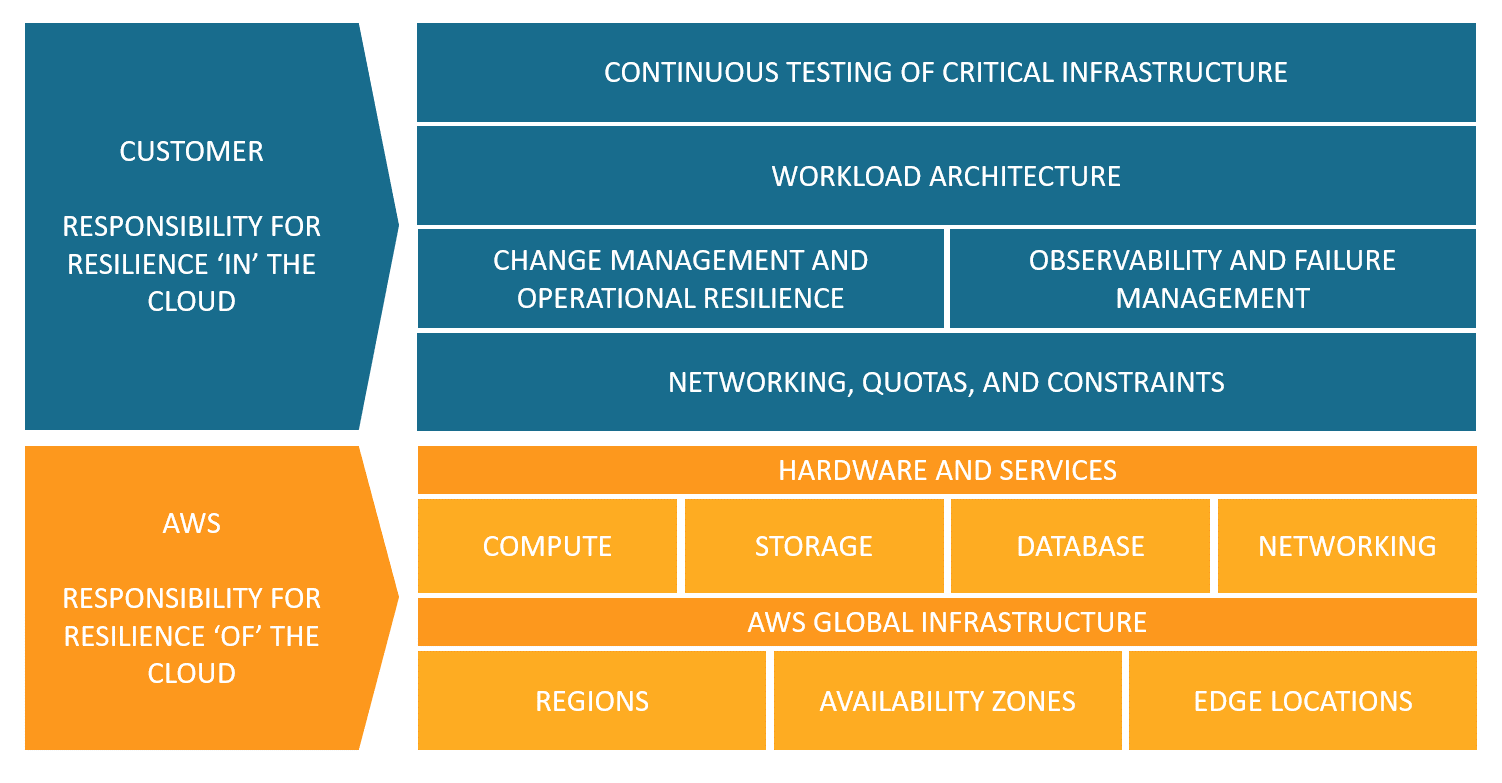
More details on this model can be found in the AWS Shared Responsibility Model for Resiliency.
This blog post explores how to integrate AWS's responsibilities with customer obligations to build resilient systems that not only meet but exceed operational excellence standards. By leveraging AWS's resilient cloud infrastructure and adopting best practices for configuring workloads, customers can achieve greater fault tolerance, reliability, and performance.
Service Availability
Availability (also referred to as service availability) serves as both a key metric for quantitatively measuring resiliency and a target objective for achieving operational excellence. When discussing availability, several critical metrics play an essential role in understanding and improving system resiliency:
-
MTTD (Mean Time to Detect)
The average time it takes to identify an issue or failure in a system. Faster detection helps mitigate problems early, reducing downtime. -
MTTR (Mean Time to Repair)
The average time required to repair a system or component and restore it to full operational status after a failure. Minimizing MTTR ensures quicker recovery and higher availability. -
MTBF (Mean Time Between Failures)
The average time a system or component operates without encountering a failure. A higher MTBF reflects better overall system stability and reliability.

Availability can be mathematically expressed using the following equation:
This equation highlights the relationship between these metrics and system availability:
- Lower MTTD enables faster issue detection.
- Lower MTTR facilitates quicker repairs and recovery.
- Higher MTBF indicates a more reliable and resilient system.
To grasp how AWS manages service availability, it's important to first understand the concepts of the control plane and data plane. For those with a background in networking and telecommunications, these may be familiar terms, but in the context of AWS, they have specific definitions. Let's explore these concepts in the AWS framework.
Control and Data Planes
AWS organizes most services into two interconnected components: the control plane and the data plane. These concepts originate from networking, particularly routers. In a router, the data plane is responsible for its primary function—moving packets based on routing rules—while the control plane manages the creation and distribution of these rules. AWS applies a similar division to its cloud services.
The control plane provides the administrative APIs that enable the management of resources through operations like Create, Read/Describe, Update, Delete, and List (CRUDL). For example, launching an Amazon EC2 instance, creating an Amazon S3 bucket, or describing an Amazon SQS queue are all control plane actions. When you launch an EC2 instance, the control plane performs various tasks such as locating a physical host with capacity, allocating network interfaces, preparing Amazon EBS volumes, generating IAM credentials, and configuring Security Group rules. These orchestration and aggregation tasks make the control plane a complex system with many moving parts, including workflows, business logic, and databases.
In contrast, the data plane handles the primary functionality of a service. It operates the core activities of AWS resources, such as running an EC2 instance, reading and writing data to an EBS volume, retrieving or storing objects in an S3 bucket, or processing DNS queries and health checks with Route 53. The data plane is designed to be simpler and more streamlined than the control plane, with fewer dependencies and moving parts. This simplicity makes the data plane statistically less likely to experience failures compared to the control plane.
Despite their differences, the control plane and data plane are tightly connected. The data plane depends on initial provisioning and configuration performed by the control plane. However, once resources are provisioned, the data plane operates independently of the control plane, which is a key factor in achieving resiliency and availability. AWS’s separation of these components ensures performance and availability benefits.
The AWS Well-Architected Framework recommends relying on the data plane over the control plane during recovery, as detailed in the guidance: Rely on the data plane and not the control plane during recovery (REL11-BP04).
Control planes are statistically more likely to fail due to their complexity, while the data plane is designed to maintain existing states and operations even during control plane disruptions. For example: in Route 53, the control plane handles routing policies and resource management but is centralized in the US East region to ensure consistency and durability. However, the data plane, responsible for answering DNS queries and performing health checks, is globally distributed and designed for a 100% availability SLA.
This separation means that even if the control plane encounters an issue, existing data plane resources and operations remain unaffected, ensuring reliability.
For disaster recovery and failover strategies, prioritize data plane functionality to ensure continuity. Although control plane APIs and consoles provide robust tools for creating and managing resources, they are not included in SLA guarantees. In rare cases, the control plane may experience disruptions while the data plane remains fully operational.
For example, in Route 53, the data plane continues answering DNS queries and performing health checks even if the control plane is temporarily impaired. This design ensures the highest possible reliability for globally distributed systems.
AWS Health
In the shared responsibility model, the availability of services running on the cloud is a collaborative effort between the cloud provider and the client. As clients, we have (typically) full control over our own services. We manage maintenance windows, monitor the availability of our resources, and address issues affecting our workloads. However, on the provider side, the cloud provider oversees their infrastructure and services. Due to this interdependent responsibility, it is crucial for customers to stay informed about the activities and status of the cloud provider.
AWS Health provides ongoing visibility into the performance of your resources and the availability of AWS services and accounts. Through AWS Health events, you can gain insights into how service or resource changes might impact your applications running on AWS. This service delivers relevant and timely information to help you:
- Manage ongoing events
- Understand and prepare for planned activities
- Troubleshoot issues efficiently
AWS Health sends alerts and notifications triggered by changes in the health of AWS resources. These alerts provide near-instant visibility into events and offer guidance to accelerate troubleshooting, helping you minimize downtime and mitigate potential impacts.
All AWS customers can monitor the health of AWS services using the AWS Health Dashboard, which a personalized view of events that affect the customer AWS account or organization Additionally, customers can receive AWS Health events via Amazon EventBridge at no extra cost. This enables automated responses or seamless integration with third-party tools, enhancing incident management and operational efficiency.
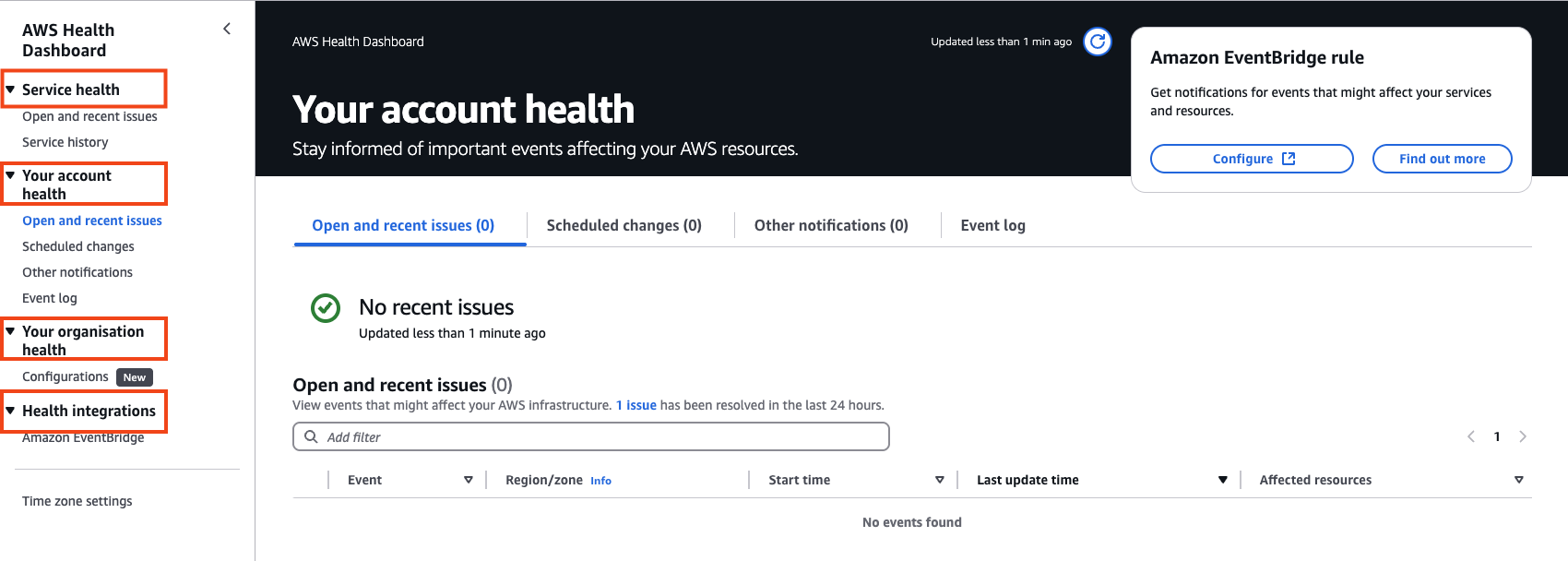
Health Events
AWS Health events, often referred to simply as Health events, are notifications sent by AWS Health on behalf of other AWS services. These events provide critical insights into upcoming or ongoing changes that could impact your AWS account. You can use these notifications to:
- Learn about scheduled changes or maintenance activities affecting your resources.
- Get updates on service availability issues in a specific AWS region.
Each event includes a detailed description, enabling you to understand the issue, identify affected resources, and take recommended actions to mitigate potential impacts.
AWS Health events are categorized into two types:
-
Public Events These are general service notifications not tied to a specific AWS account. For instance, if there is a service issue in an AWS region, AWS Health provides event details—even if your account does not have resources in that region.
-
Account-Specific Events These events are tied to your AWS account or an account within your organization. For example, if an issue arises with EC2 in a region where you have resources, AWS Health sends a detailed notification about the problem, including affected resources and recommended actions.
You can use Amazon EventBridge to detect and respond to AWS Health events automatically. EventBridge allows you to create rules based on event parameters, triggering one or more target actions when an event matches your specified criteria. For more details, refer to the official documentation: AWS Health Events and Amazon EventBridge.
While the AWS Health Tools GitHub project hasn’t been actively maintained, it still offers valuable ideas and examples for automating and integrating AWS Health notifications. You can explore the repository here: AWS Health Tools GitHub.
AWS Health API Use Case
Let’s examine a scenario from ARC317 Chalk Talk, whitch illustrate the importance of integrating the AWS Health API:
Between 8:00 AM and 9:00 AM, a nationwide point-of-sale (POS) system experienced 100% request failures. The root cause was a scheduled maintenance activity to upgrade a core database cluster. This maintenance, planned to complete within 15 minutes and two hours before store opening, unexpectedly overran its schedule, causing the disruption.
In this case, the issue was caused by AWS RDS service maintenance. Although AWS was performing the maintenance in the background, the customer was unaware of this activity, leading to the upgrade being carried out at an inopportune time.
While customers can manually monitor service health using the AWS Health Dashboard or receive notifications through AWS Health EventBridge integration, relying on manual checks or notifications alone can leave gaps. Automation offers a more effective and proactive approach to avoiding such scenarios.
The AWS Health API provides programmatic access to AWS Health data, enabling applications to query service health status in real time. As a RESTful service, the API uses HTTPS for transport and JSON for message serialization, making it easy to integrate into existing workflows.
A common use case for the AWS Health API is integrating it into CI/CD pipelines to ensure service health before critical deployments or upgrades. In the scenario above, if the customer had queried the AWS Health API for the status of AWS RDS before starting the upgrade, they would have been alerted to the ongoing maintenance. For example, in the RDS upgrade scenario:
- Before initiating the upgrade job, the pipeline queries the AWS Health API to verify the health of the required AWS services (e.g., RDS).
- If maintenance events or service issues are detected, the pipeline halts the process, notifies stakeholders, or triggers an alternative workflow.
- If no issues are identified, the pipeline proceeds with the deployment or upgrade as planned.
This proactive approach minimizes risks associated with scheduled maintenance or service disruptions, ensuring smoother operations and higher reliability.
When using the AWS Health API, keep the following considerations in mind:
- Support Plan Requirements
To access the AWS Health API, your account must be subscribed to a Business, Enterprise On-Ramp, or Enterprise Support plan from AWS Support.
If you attempt to call the AWS Health API from an account without one of these support plans, you will encounter a SubscriptionRequiredException error.
- Active-Passive Regional Endpoints
The AWS Health API provides two regional endpoints in an active-passive configuration. To simplify DNS failover, AWS Health offers a single global endpoint.
Both the active and passive endpoints provide AWS Health data, but the latest and most accurate data is only available from the active endpoint. Data from the passive endpoint is eventually consistent. If the active endpoint changes, AWS recommend restarting any workflows to ensure consistency.
To identify the active endpoint, you can use the following dig commands:
> dig global.health.amazonaws.com
global.health.amazonaws.com. 10 IN CNAME health.us-east-1.amazonaws.com.
health.us-east-1.amazonaws.com. 60 IN CNAME prod.us-east-1.health-api.external.silvermine.aws.a2z.com.
Retrieve active endpoint directly:
dig global.health.amazonaws.com | awk '/CNAME/ && /global/ {print $5}'
- Accessing Service Health Data
You can access AWS Health data using either the API or the CLI. The DescribeEvents operation retrieves information about events that meet specified filter criteria. The returned data includes event summaries but does not provide detailed descriptions, metadata specific to the event type, or information about affected resources.
aws health describe-events \
--filter "services=EC2 eventStatusCodes=open,upcoming, regions=eu-north-1" \
--region us-east-1
By using filter criteria, you can tailor the results to focus on specific services, event statuses, and regions. This is particularly useful for identifying ongoing or upcoming issues that could impact your resources and operations.
"filter": {
"availabilityZones": [ "string" ],
"endTimes": [
{
"from": number,
"to": number
}
],
"entityArns": [ "string" ],
"entityValues": [ "string" ],
"eventArns": [ "string" ],
"eventStatusCodes": [ "string" ],
"eventTypeCategories": [ "string" ],
"eventTypeCodes": [ "string" ],
"lastUpdatedTimes": [
{
"from": number,
"to": number
}
],
"regions": [ "string" ],
"services": [ "string" ],
"startTimes": [
{
"from": number,
"to": number
}
],
"tags": [
{
"string" : "string"
}
]
}
I have also provided a solution to check the status of AWS services before deploying resources. Currently, the Terraform AWS providers (both aws and awscc) do not include any data blocks for checking AWS service health. The example below demonstrates how to achieve this using Terraform in combination with a Python script:
s3-with-health-check.tf
# Terraform external data block
data "external" "radlands" {
program = ["python3", "./health.py"]
query = {
services = "S3"
regions = "eu-north-1,eu-west-1"
}
}
# Terraform s3 bucket - conditional creation
resource "aws_s3_bucket" "radlands" {
bucket = "cloudynotes-io-radlands"
lifecycle {
precondition {
condition = data.external.radlands.result.events == jsonencode([])
error_message = "Service health check failed: ${data.external.radlands.query.services} are not in a healthy state."
}
}
}
# Output health_events and active_endpoint
output "health_events" {
value = data.external.radlands.result.events
}
output "health_active_endpoint" {
value = data.external.radlands.result.active_aws_health_region
}
# Provider block
terraform {
required_providers {
external = {
source = "hashicorp/external"
version = "2.3.4"
}
aws = {
source = "hashicorp/aws"
version = "5.82.2"
}
}
}
health.py
import boto3
import json
import sys
import subprocess
def get_active_aws_health_region():
"""
Retrieve the active AWS Health API region by resolving the global.health.amazonaws.com CNAME.
Returns:
str: The active region endpoint (e.g., 'health.us-east-1.amazonaws.com') or None if unsuccessful.
"""
try:
result = subprocess.run(
["dig", "global.health.amazonaws.com", "+short"],
capture_output=True,
text=True
)
# Extract the CNAME from the output
for line in result.stdout.splitlines():
if line.endswith(".amazonaws.com."):
active_endpoint = str(line.strip().split(".")[1])
return active_endpoint
except Exception as e:
print(f"Error retrieving active AWS Health region: {e}")
return None
def get_aws_health_events(services, event_status_codes, regions):
"""
Fetch AWS Health events based on filter criteria and return a JSON object suitable for Terraform Data block.
Parameters:
services (list): List of AWS services to filter (e.g., ["EC2"]).
event_status_codes (list): List of event statuses (e.g., ["open", "upcoming"]).
regions (list): List of regions to filter (e.g., ["eu-north-1"]).
Returns:
dict: JSON object containing the events as a string.
"""
# Create a Boto3 Health client
active_aws_health_region = get_active_aws_health_region()
health_client = boto3.client('health', region_name=active_aws_health_region)
# Define the filter criteria
filter_criteria = {
"services": services,
"eventStatusCodes": event_status_codes,
"regions": regions
}
try:
# Call the AWS Health DescribeEvents API
response = health_client.describe_events(
filter=filter_criteria
)
# Extract only the events
events = response.get("events", [])
return {"events": json.dumps(events), "active_aws_health_region": active_aws_health_region}
except health_client.exceptions.SubscriptionRequiredException as e:
return {"error": "A Business or Enterprise Support plan is required."}
except Exception as e:
return {"error": "An unexpected error occurred."}
if __name__ == "__main__":
# Parse input from Terraform
input_params = json.load(sys.stdin)
services = input_params.get("services", "").split(",")
event_status_codes = ["open", "upcoming"] # Fixed as per original request
regions = input_params.get("regions", "").split(",")
result = get_aws_health_events(services, event_status_codes, regions)
print(json.dumps(result))
The below code block shows the terraform output result:
Changes to Outputs:
+ health_active_endpoint = "us-east-1"
+ health_events = jsonencode([])
Discussion
Resilience is not an isolated consideration—it must be integrated into operations and design. Avoid relying solely on default configurations; instead, tailor your system to meet operational needs. Checking AWS Health before deployments is crucial, particularly if deployments occur frequently. It’s equally important to consider all stakeholders and components that play critical roles in ensuring your service availability.
A common question arises: If a service is unhealthy, should we always stop the deployment? The answer depends on the type of change or deployment. However, according to the AWS Well-Architected Framework guideline OPS06-BP01 - Plan for Unsuccessful Changes, the recommended approach is to plan to revert to a known good state or implement remediation strategies in the production environment to address any undesired outcomes caused by the deployment.
Another point of debate regarding AWS Health is: Why doesn’t AWS automatically prevent customer activities that might interfere with ongoing AWS maintenance or service disruptions? While this could improve resiliency and reduce errors, such a feature does not currently exist. This idea could be proposed to AWS through their working backward process as a potential feature request.